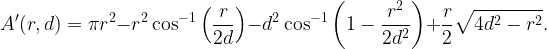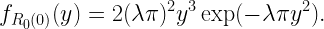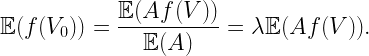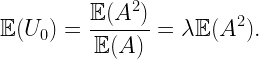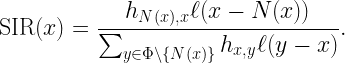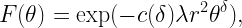What do you tell somebody who wants to use the Palm measure but does not condition on a point at the origin?


“You are missing the point.”
A blog on stochastic geometry
Author: Martin Haenggi
What do you tell somebody who wants to use the Palm measure but does not condition on a point at the origin?
“You are missing the point.”
In this post I would like to show how meta distributions naturally emerge as an important extension of the concepts of averages and distributions. For a random variable Z, we call 𝔼(Z) its average (or mean). If we add a parameter z to compare Z against and form the family of random variables 1(Z>z), we call their mean the distribution of Z (to be precise, the complementary cumulative distribution function, ccdf for short).
Now, if Z does not depend on any other randomness, then 𝔼1(Z>z) gives the complete information about all statistics of Z, i.e., the probability of any event can be expressed by adding or subtracting these elementary probabilities.
However, if Z is a function of other sources of randomness, then 𝔼1(Z>z) does not reveal how the statistics of Z depend on those of the individual random elements. In general Z may depend on many, possibly infinitely many, random variables and random elements (e.g., point processes), such as the SIR in a wireless network. Let us focus on the case Z=f(X,Y), where X and Y are independent random variables. Then, to discern how X and Y individually affect Z, we need to add a second parameter, say x, to extend the distribution to the meta distribution:
Alternatively,
Hence the meta distribution (MD) is defined by first conditioning on part of the randomness. It has two parameters, the distribution has one parameter, and the average has zero parameters. There is a natural progression from averages to distributions to meta distributions (and back), as illustrated in this figure:

From the top going down, we obtain more information about Z by adding indicators and parameters. Conversely, we can eliminate parameters by integration (taking averages). Letting U be the conditional ccdf given Y, i.e., U=𝔼X1(Z>z)=𝔼[1(Z>z) | Y], it is apparent that the distribution of Z is the average of U, while the MD is the distribution of U.
Let us consider the example Z=X/Y , where X is exponential with mean 1 and Y is exponential with mean 1/μ, independent of X. The ccdf of Z is
In this case, the mean 𝔼(Z) does not exist. The conditional ccdf given Y is the random variable
and its distribution is the meta distribution
As expected, the ccdf of Z is retrieved by integration over x∈[0,1]. This MD has relevance in Poisson uplink cellular networks, where base stations (BSs) form a PPP Φ of intensity λ and the users are connected to the nearest BS. If the fading is Rayleigh fading and the path loss exponent is 2, the received power from a user at an arbitrary location is S=X/Y, where X is exponential with mean 1 and Y is exponential with mean 1/(λπ), exactly as in the example above. Hence the MD of the signal power S is
So what additional information do we get from the MD, compared to just the ccdf of S? Let us consider a realization of Φ and a set of users forming a lattice (any stationary point process of users would work) and determine each user’s individual probability that its received power exceeds 1:

If we draw a histogram of all the user’s probabilities (the numbers in the figure), how does it look? This cannot be answered by merely looking at the ccdf of S. In fact ℙ(S>1)=π/(π+1)≈0.76 is merely the average of all the numbers. To know their distribution, we need to consult the MD. From (1) the MD (for λ=1 and z=1) is 1-xπ. Hence the histogram of the numbers has the form of the probability density function πxπ-1. In contrast, without the MD, we have no information about the disparity between the users. Their personal probabilities could all be well concentrated around 0.76, or some could have probabilities near 0 and others near 1. Put differently, only the MD can reveal the performance of user percentiles, such as the “5% user” performance, which is the performance that 95% of the users achieve but 5% do not.
This interpretation of the MD as a distribution over space for a fixed realization of the point process is valid whenever the point process is ergodic.
Another application of the MD is discussed in an earlier post on the fraction of reliable links in a network.
When simulating a point process to characterize the performance of the typical point (typical user or receiver), a conditioned version of the point process given a point at the origin o may not be available. It is then tempting to choose the “next best” point as a substitute, which may be the point closest to the origin. (Whether the coordinates are then shifted so that this point is at o is irrelevant.) The goal of this post is to show that this point is not typical, i.e., producing many realizations of the point process and evaluating the performance at this point does not yield the performance of the typical point. I call the point closest to o after averaging over the point process the 0-point. Put differently, the 0-point is the typical point among all points closest to o across the realizations of the point process. In a cellular network, the 0-point is the nucleus of the 0-cell (see this post), hence the term.
For simplicity, let us consider the homogeneous PPP of intensity 1 and focus on the probability that a disk of radius r centered at a point contains no other points, which we refer to as the NOPID (no other point in disk) probability. Equivalently, it is the probability that the nearest neighbor is at distance at least r. For the typical point, the NOPID probability is exp(-πr2). For the 0-point, let D be its distance from o. Given D, the disk of radius D centered at o, denoted as b(o,D), is empty, so the points excluding the 0-point form a PPP on ℝ2\b(o,D), and the NOPID probability is the probability that b((D,0),r)\b(o,D) is empty. This region is shown in blue in the movie below for different r given that the 0-point is at (1,0), i.e., D=1. For r<2D, it is moon- or crescent-shaped, while for r>2D, it is a disk with a hole.
Letting A(r,d)=|b((d,0),r)\b(o,d)|, the (unconditioned) NOPID probability is 𝔼(exp(-A(r,D)), where D is Rayleigh distributed with mean 1/2. It can be expressed as
where
is the area A(r,d) for r<2d. For r>2d, A(r,d)=π(r2–d2), which results in the first term in (1).
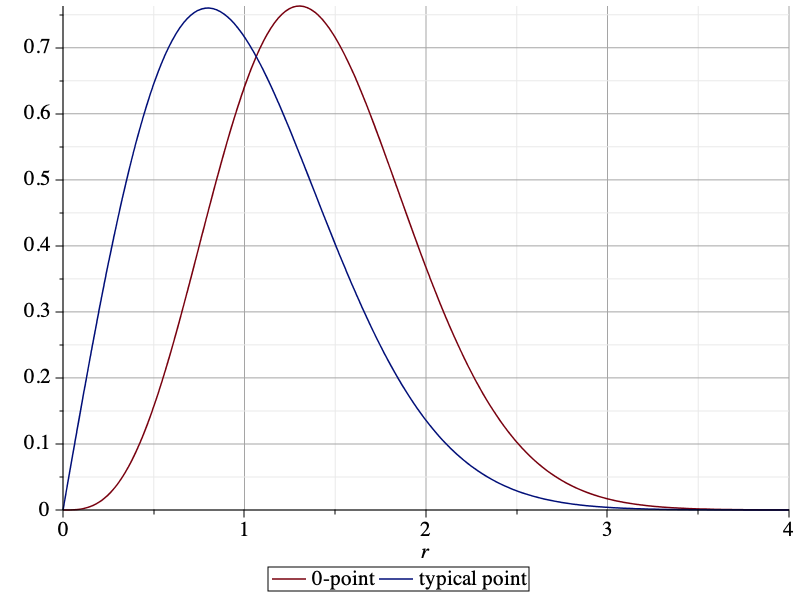
The NOPID probabilities of the 0-point and the typical point are compared below. It is apparent that the 0-point is more isolated than the typical point.

By integrating the NOPID probability of the 0-point, we obtain the mean nearest-neighbor distance as 0.5953. This is almost 20% larger than that of the typical point, which is 1/2. The difference between the two NOPID probabilities is not just in the mean, though. They differ qualitatively in the tail. For large r, it follows from (1) that the ratio of the two NOPID probabilities approaches πr2/4. This implies that a Rayleigh distribution with adjusted mean will not provide a good fit to the NOPID probability at the 0-point.
The difference is even more pronounced if we consider directional nearest neighbors. If we consider a sector of angle π/2, then the nearest neighbor of the typical point is at distance 1 on average, irrespective of the orientation of the sector. For the 0-point, in the direction opposite from o, the mean distance is also 1, since on that side, the PPP is unaffected by the empty disk b(o,D). In the direction towards o, however, the distance is significantly larger, with a mean of 1.4205. The plot below shows the pdf of the directional nearest-neighbor distance of the 0-point oriented towards o (red) and the pdf of the directional nearest-neighbor distance of the typical point (blue), given by (π/2)r exp(-(π/4)r^2). The pdfs are the negative derivatives of the NOPIS (no other point in sector π/2) probabilities.
When applied to cellular networks (with nearest-base station association), the 0-point is the base station serving the typical user (at o). The discussion here reveals that the 0-base station behaves differently from the typical base station. In particular, the point process of the other base stations viewed from the 0-base station is highly non-isotropic. In the direction of the typical user, the nearest other base station is much further away than in the opposite direction. This fact is consistent with the conclusions from this post on the shape of the 0-cell in the Poisson-Voronoi tessellation.
In this blog we are exploring the shape of two kinds of cells in the Poisson-Voronoi tessellation on the plane, namely the 0-cell and the typical cell. The 0-cell is the cell containing the origin, while the typical cell is the cell obtained by conditioning on a Poisson point to be at the origin (which is the same as adding the origin to the PPP).
The cell shape has an important effect on the signal and interference powers at the typical user (in the 0-cell) and at the user in the typical cell. For instance, in the 0-cell, which contains the typical user at a uniformly random location, about 1/4 of the cell edge is at essentially the same distance to the base station as the typical user on average). Hence it is not the case that edge users necessarily suffer from larger signal attenuation than the typical user (who resides inside the cell).
The cell shape is determined by the directional radii of the cells when their nucleus is at the origin. To have a well-defined orientation, we select a location uniformly in the cell and rotate the cell so that this location falls on the positive x-axis. In the 0-cell, this involves first a translation of the cell’s nucleus to the origin, followed by a rotation until the original origin (which is uniformly distributed in the cell) lies on the positive x-axis. This is illustrated in Movie 1 below. In the typical cell, it involves adding a Poisson point, selecting a uniform location, and a rotation so that this uniform location lies on the positive x-axis. This is illustrated in Movie 2.
As indicated in the movies, the distances from the nucleus to the uniformly random location are denoted by D0 and D, respectively, and the directional radii by R0(ϕ) and R(ϕ), respectively. This way, the boundary of the cells is described in polar coordinates as (R0(ϕ),ϕ) and (R(ϕ),ϕ), ϕ ∈ [0,2π). In a cellular network model, the uniform random location could be that of a user, while the PPP models the base stations. In this case D0 is the link distance from the typical user to its serving base station, while D is the link distance from the typical base station to a randomly located user it serves. The distinction between the typical user’s and the typical base station’s point of view is explained in this blog.
Let λ denote the density of the PPP. Three results are well known:
In contrast, there is no closed-form expression for the distribution of D. Due to size-biased sampling, the area of the 0-cell stochastically dominates that of the typical cell and, in turn, D0 dominates D.
Analyzing the directional radii, we obtain these new insights on the cell shapes:
In conclusion, the 0-cell and the typical cell are quite asymmetric around the nucleus (base station) and the uniformly random point (user). In the direction away from the base station, the user is about 4 times closer to the cell edge than in the direction towards the base station, and many locations on the cell edge are closer to the base station than the user inside the cell. These results have implications on the design of efficient cellular network transmission schemes, such as beamforming, NOMA, and base station cooperation, in both down- and uplink.
More details are available in Section II of this paper.
What do you call a stationary point process of intensity 0?
Pointless.
The analysis of cellular networks usually focuses on the typical user in the downlink and the typical base station (or, equivalently, the typical cell) in the uplink. It is important that if base station and user point processes are independent, the two notions of “typical” are not compatible – the typical user’s cell is statistically different from the typical cell. The difference is caused by the effect of size-biased sampling. The typical user’s performance corresponds to that of the average of all users, and there are more users in larger cells. Since a user model is not needed in the downlink as explained in this post, we can equivalently say that an arbitrary location is more likely to fall in a larger cell than a smaller cell.
The typical user’s cell, the so-called 0-cell, is the cell containing the origin, i.e., it is obtained by cell area-biased sampling, which gives larger cells more weight. As a result, the 0-cell is larger on average than the typical cell, which is the cell of the base station conditioned to be at the origin. The statistical properties of the typical cell correspond to the averages of all cells.
Such size-biased sampling is not restricted to cellular networks or stochastic geometry. If we throw a dart blindly on a world map until we hit land, the country we hit is quite likely to be a big one. In fact, there is a 50% chance that the dart lands on one of the 10 largest countries. Similarly, the typical country has 40 M inhabitants on average, but the typical person is likely to live in a country with more than 100 M people. The typical dollar is quite likely owned by a wealthy person, while the typical person is probably not rich. The typical human hair is likely to grow on a person with full hair, while the typical person has a 5-10% chance of being bald. The typical animal leg has a decent chance of belonging to a millipede or centipede, while the typical animal is very unlikely to have more than six feet.
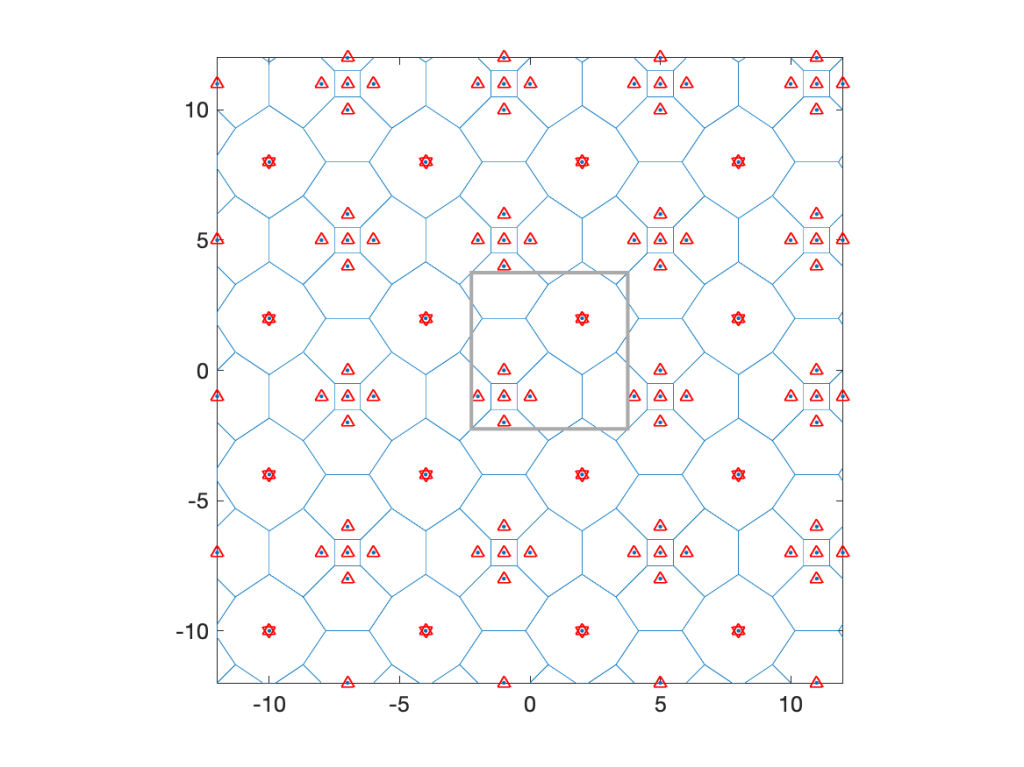
Coming back to cellular networks, let us focus on a concrete example that is fully tractable in terms of the cell area distributions. Consider the lattice with holes shows in Fig. 1 below, obtained from a square lattice of density 1 by removing the four nearest neighbors of each 16th point. It is periodic with period 4 in both directions, its density is λ=3/4, and it has four different types of cells, with three different areas, 1, 3/2, and 2.

The typical cell has area 1 with probability 5/12, area 3/2 with probability 1/2, and area 2 with probability 1/12. The mean area follows as E(A)=5/12+1/2 3/2+1/12 2=4/3, which corresponds to 1/λ.
Now assume a stationary square lattice of density 1 as the user point process. Then the cells of area 1 always contain 1 user and those of area 2 always contain 2 users. Those of area 3/2 have 1 user or 2 users, each with probability 1/2. Deconditioning on the cell areas, we obtain the distribution of the number of users U in the typical cell as P(U=1)=2/3 and P(U=2)=1/3, for a mean number of users E(U)=4/3, which equals the mean area times the user density (chosen to be 1 here).
How about the typical user’s cell? This is where the size bias plays a role. The distribution of the area A0 of the 0-cell is P(A0=1)=5/16, P(A0=3/2)=9/16, and P(A0=2)=1/8. These are the fractions of the plane covered by cells of areas 1, 3/2, and 2. The mean area is E(A0)=45/32, which is about 5.5% bigger than the mean area of the typical cell. The number of users U0 in the 0-cell is distributed as P(U0=1)=5/16+1/2 9/16=19/32, P(U0=2)=1/2 9/16+1/8=13/32, resulting in a mean of E(U0)=45/32, which is the user density times the mean area. The mean also follows from the general formula
where V is the typical cell, V0 the 0-cell, and f is a non-negative function on compact sets. Applied to our setting, where f(V) is the number of users in V, we obtain
Since the user density is 1, this is also the mean area of A0. For the number of sides S, we have E(S)=19/4, but E(S0)=155/32, which is bigger by 3/32.
At the end of this post are three more examples of similarly constructed lattices. In each case, the points within a certain distance of a sub-lattice are removed.
So the typical user is not served by the typical base station, and the typical base station does not serve the typical user. One way to reconcile the two is to define a user point process where a fixed number of users, say one, is placed uniformly at random in each cell. Such a user process is of course no longer independent of the base station process.
For Poisson distributed base stations, the 0-cell is 28% larger than the typical cell. Its mean number of sides is 6.41, whereas the typical cell has 6 sides on average. Hence the 0-cell is not just an enlarged version of the typical cell but also has a different shape. Accordingly, the distance from the nucleus of the typical cell to a random point in the cell is not Rayleigh distributed as it is in the 0-cell. Also, if users form a PPP of density 1, the typical user’s cell has 1+1.28/λ users on average (there is one extra user due to the conditioning of a user to be at the origin), while the typical cell only has a mean of 1/λ users.
Size-biased sampling is important in other wireless networks as well. If a vehicular network is modeled by placing one-dimensional Poisson point processes (cars) on line segments (streets) of independent random length (which is a Cox process supported on line segments), then the typical vehicle’s street length distribution fL0 is different from the length distribution f_L of the streets. By length-biased sampling, the two are related as
For example, if L is exponential with mean 1, then L0 is gamma distributed with mean 2. The same situation arises in the interarrival intervals of a one-dimensional PPP (of density 1). The typical such interval is exponential with mean 1, but the interval containing the origin (or any other deterministic time instant) has a mean length of 2. This is sometimes referred to as the waiting time paradox, although there is nothing paradoxical about it – it is just size-biased sampling.
Lastly, as promised, here are three more examples of lattices with increasingly large holes.


In recent years, many research efforts were dedicated towards modeling and analyzing denser and denser wireless networks, in terms of the number of devices per km2 or m2. The terminology used ranges from “ultradense” to “hyperdense”, “massively dense”, and “extremely dense”.
IEEE Xplore lists more than 500 journal papers on “ultradense” networks, 25 on “hyperdense” networks (generally published more recently than the ultradense ones), and about 90 on “extremely dense” networks. There even exist 15 on “massively dense” networks. The natural question is how they are ordered. Is “ultradense” denser than “hyperdense” or vice versa? How does “extremely dense” fit in? Are there clear definitions what the different levels of densities mean? And what term do we use when networks get even denser?
Perhaps we can learn something from the terminology used for frequency bands. There is “high frequency” (HF), “very high frequency” (VHF), “ultrahigh frequency” (UHF), followed by “super high frequency” (SHF), “extremely high frequency” (EHF), and “tremendously high frequency” (THF). The first five each span an order of magnitude in frequency (or wavelength), while the last ones spans two order of magnitude, from 300 GHz to 30 THz.
So how about we follow that approach and classify network density levels as follows:
HD: 1-10 km-2
VHD: 10-100 km-2
UHD: 100-1’000 km-2
SHD: 1’000-10’000 km-2
EHD: 10’000-100’000 km-2
THD: 0.1-10 m-2
So, who will be the first to write a paper on tremendously dense networks?
What comes after THD? Not unexpectedly, there is a mathematical answer to that question. A dense set has a well-defined meaning. So in the super tremendously extreme case, we can just say that the devices are dense on the plane, without further qualification. This is achieved, for instance, by placing a device at each location with rational x and y coordinates. This is a dense network model, and almost surely there is no denser one.
The attributes “tractable”, “closed-form”, and “exact” are frequently used to describe analytical results and, in the case of “tractable”, also models. At the time of writing, IEEE Xplore lists 4540 journal articles with “closed-form” and “wireless” in their meta data, 650 with “tractable” and “wireless”, and 220 with “closed-form”, “wireless” and “stochastic geometry”.
Among the three adjectives, only for “exact” there is general consensus what is means exactly. For “closed-form”, mathematicians have a clear definition: The expression can only consist of finite sums and products, division, roots, exponentials, logarithms, trigonometric and hyperbolic functions and their inverses. Many authors are less strict, using the term also for expressions involving general transcendent functions or infinite sums and products. Lastly, the use of “tractable” varies widely. There are “tractable results”, “tractable models”, “tractable analyses”, and “tractable frameworks”.
“Tractable” is defined by Merriam-Webster as “easily handled, managed, or wrought”, by the Google Dictionary as “easy to deal with”, and by the Cambridge Dictionary as “easily dealt with, controlled, or persuaded”. Wikipedia refers to the mathematical use of the term: “ease of obtaining a mathematical solution such as a closed-form expression”. These definitions are too vague to clearly distinguish a “tractable model” from a “non-tractable” one, since “easy” can mean very different things to different people.
We also find combinations of the terms; in the literature, there are “tractable closed-form expressions” and even “highly accurate simple closed-form approximations”. But shouldn’t all “closed-form” expressions qualify as “tractable”? And aren’t they also “simple”, or are there complicated “closed-form” expressions?
It would be helpful to find an agreement in our community what qualifies as “closed-form”. Here is a proposal:
Thus equipped, we could try to define what a “tractable model” is. For instance, we could declare a model “tractable” if it allows the derivation of at least one non-trivial exact closed-form result for the metric of interest. This way, the SIR distribution in the Poisson bipolar network with ALOHA, Rayleigh fading, and power-law path loss is tractable because the expression only involves an exponential and a trigonometric function. The SIR in the downlink Poisson cellular with Rayleigh fading and path loss exponent 4 is also tractable; its expression includes only square roots and an arctangent. In contrast, the SIR in the uplink Poisson cellular network is not tractable, irrespective of the user point process model.
A result could be termed “tractable” if the typical educated reader can tell how the expression behaves as a function of its parameters.
Going a step further, it may make sense to be more formal and introduce categories for the sharpness of a result, such as these:
A1: closed-form exact
A2: weakly closed-form exact
A3: general exact
B1: closed-form bound
B2: weakly closed-form bound
B3: general bound
C1: closed-form approximation
C2: weakly closed-form approximation
C3: general approximation
Alternatively, we could use A+, A, A-, B+, etc., inspired by the letter grading system used in the USA. We could even calculate a grade point average (GPA) of a set of results, based on the standard letter grade-to-numerical grade conversion.
Such classification allows a non-binary quantification of “tractability” of a model. If the model permits the derivation of an A1 result, it is fully “tractable”. If it only allows C3 results, it is not “tractable”. If we can obtain, say, an A3, a B2, and a C1 result, it is 50% “tractable” or “semi-tractable”. Such a sliding scale instead of a black-and-white categorization would reflect the vagueness of the general definition of the term but put it on a more solid quantitative basis. Subcategories for asymptotic results or “order-of” results could be added.
This way, we can pave the way towards the development of a tractable framework for tractability.
Let us consider the downlink of a cellular network where base stations form a stationary and ergodic point process Φ and define the SIR at each location x ∈ R2 as
Here N(x) is the nucleus of the Voronoi cell that x belongs to, hx,y is the fading coefficient between x and y, and ℓ is the path loss function. Due to the stationarity of Φ, the SIR statistics do not depend on the location x. In other words, any arbitrary location can be taken to be the typical location that the analysis focuses on.
Example result: If Φ is Poisson, the fading is Rayleigh, and ℓ is a power-law function with exponent 2/δ, it is known that for all x ∈ R2,
where 2F1 is the Gauss hypergeometric function.
Since Φ is ergodic, the probability that the SIR exceeds θ is the fraction of the plane that achieves an SIR of at least θ for all realizations of Φ. This means that the probability (ensemble average) can be replaced by a spatial average over an increasingly large region. Sometimes this probability (or spatial average) is questionably called “coverage probability” (see this post), and the area fraction is termed “covered area fraction”.
It is important to note that results such as (1) do not require any specification of a point process of users. This answers the question in the title: No, users are not necessary in the downlink SIR analysis.
That said, in the literature we observe that in many cases, a point process of users is defined before such downlink SIR results are derived. The reason could be that it may seem overly abstract to consider a cellular network model devoid of any users and view the SIR as a random field on the plane. Specializing the location x to the points of a user point process (assumed independent of Φ), we observe that (1) is the SIR distribution at the typical user for any stationary point process of users. So there is nothing wrong in introducing a point process of users, focus on the typical user, and state a result such as (1). It would, however, be potentially misleading to specify the user point process to be a Poisson process, since the reader may then believe that the result only holds for Poisson distributed users.
There is one caveat when introducing a point process of users to formulate downlink results: The interpretation of the SIR distribution as the fraction of users who achieve SIR>θ in each realization of the user and base station point processes may no longer be correct, even if the two point processes are independent and stationary and ergodic. For instance, consider the case where both are stationary (i.e., randomly translated) lattices of the same intensity. Then, given the point processes, the SIR distribution at each user is the same and depends on the relative shift of the lattices. For example, if a user is very close to its serving base station, then all users are close to their serving base station, and the SIR at all users is likely to exceed θ even when θ is, say, 20 dB. In contrast, if one user is equidistant to two base stations, then all users are, and it is unlikely that the SIR (at any or all of them) exceeds 1. So averaging over the users in one realization cannot yield the same result as averaging over the point processes (ensemble averaging). But doesn’t ergodicity imply that the two results are the same? The answer is yes, it does, but individual ergodicity of the two point processes is not sufficient. Since the SIR depends on both of them jointly, they need to be jointly ergodic. This is the condition that is not met in this example scenario of two lattices.
Sometimes we read in a paper “the link distance is d meters”. Then, a bit later, “In Fig. 3, we set d=10 m”. Putting the two together, this means that “the link distance is 10 m meters”, which of course isn’t what the authors mean. It is not hard to infer that they mean the distance is 10 m, rather than 10 m2. But then why not just say “the link distance is d” from the outset?
Physical quantities are a combination of a numerical value and a unit. If symbols refer to physical quantities, equations are valid irrespective of any metric prefixes used. For example, if the density of a two-dimensional stationary point process is λ, then the mean number of points in a disk of radius r is always λπr2. We can express the radius as r=100 m or as r=0.1 km or r=10000 cm, and the density could be λ=0.1 km-2 or λ=10-5 m-2. In contrast, if a symbol only refers to the numerical value of the physical quantity, the underlying unit (and prefix) needs to be specified separately, and the reader needs to keep it in mind. For example, writing λ=10 and r=2 does not tell us anything about the mean number of points in the disk without the units. If the density is said to be λ m-2 and the radius is said to be r km, then we can infer that there are 40,000,000π points on average in the disk, but if the radius is r m, then there are a mere 40π points.
Separating the numerical values from the units also comes at a loss in flexibility. The advantage of the SI unit system with its metric prefixes is that we can express small and large values conveniently, such as d=5 nm or f=3 THz. Hard-wiring the units by saying “the frequency is f Hz” means that we have to write f=3,000,000,000,000 instead – and expect the reader to memorize that f is expressed in Hz. One may argue that in this case it would be natural to declare that “the frequency is f THz”, but what if much lower frequencies also appear in the paper? A Doppler shift of 10 kHz would become a Doppler shift of f=0.00000001.
This leads to the next problem, which is that some quantities are naturally expressed at a different scale (i.e., with a different metric prefix) than others. Transistor gate lengths are usually expressed in nm, while lengths of fiber optic cables may be expressed in km, and many other lengths and distances fall in between, say wavelengths, antenna spacing, base station height, intervehicular distances etc. Can we expect the readers to keep track of all the base units when we write “the gate length is u nm”, “the wavelength is v cm”, and “the base station height is h m”?
In conclusion, there is really no advantage to this kind of separation. In other words, having mathematical symbols refer to physical quantities rather than just numerical values (while the unit is defined elsewhere) is always preferable.
Now, there are cases, where it makes perfect sense to omit a unit when defining a quantity, say a density or a distance. For example, the normalized notation r=10 or λ=3 is acceptable (usually even preferred) when the normalization reference can be arbitrary. For example, the classical result for the SIR distribution in Poisson bipolar networks (link distance r, path loss exponent 2/δ, Rayleigh fading) is
irrespective of whether r is normalized by 1 m or 1 km – as long as λ is normalized accordingly, i.e., by 1 m-2 or 1 km-2). Such scale-free results are particularly elegant, because they show that shrinking or expanding the network does not change the result. They may also indicate that one parameter can be fixed without loss of generality. In this example, what matters is the product λ r2, so setting λ=1 or r=1 is sensible to reduce the number of parameters.
One more thing. The conflation of a unit and a noun describing a physical quantity or device has become somewhat popular, unfortunately. It violates rule of proper English composition and also the guidelines for scientific writing as put forth by, for example, IEEE. Let us hope they do not spread further, otherwise we need to get used to THzFrequencies, cmDistances, MsLifetimes, pJConsumptions, km-2Densities etc. Further, improper capitalization can drastically change the quantities. The gap between a mmLength and a MmLength is 9 orders of magnitude, that between a pASource and a PASource is 27 orders of magnitude, and that between ymGaps and YmGaps is 48 orders of magnitude!
![\displaystyle \bar F_{[\![Z\mid Y]\!]}(z,x)=\mathbb{E}\mathbf{1}(\mathbb{E}[\mathbf{1}(Z>z) \mid Y]>x).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar+F_%7B%5B%5C%21%5BZ%5Cmid+Y%5D%5C%21%5D%7D%28z%2Cx%29%3D%5Cmathbb%7BE%7D%5Cmathbf%7B1%7D%28%5Cmathbb%7BE%7D%5B%5Cmathbf%7B1%7D%28Z%3Ez%29+%5Cmid+Y%5D%3Ex%29.&bg=ffffff&fg=000000&s=2&c=20201002)
![\displaystyle \bar F_{[\![Z\mid Y]\!]}(z,x)=\mathbb{E}\mathbf{1}(\mathbb{E}_X\mathbf{1}(Z>z)>x).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar+F_%7B%5B%5C%21%5BZ%5Cmid+Y%5D%5C%21%5D%7D%28z%2Cx%29%3D%5Cmathbb%7BE%7D%5Cmathbf%7B1%7D%28%5Cmathbb%7BE%7D_X%5Cmathbf%7B1%7D%28Z%3Ez%29%3Ex%29.&bg=ffffff&fg=000000&s=2&c=20201002)


![\displaystyle \bar F_{[\![Z\mid Y]\!]}(z,x)\!=\!\mathbb{P}(U\!>\!x)\!=\!\mathbb{P}(Y\!\leq\!-\log(x)/z)\!=\!1\!-\!x^{\mu/z}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar+F_%7B%5B%5C%21%5BZ%5Cmid+Y%5D%5C%21%5D%7D%28z%2Cx%29%5C%21%3D%5C%21%5Cmathbb%7BP%7D%28U%5C%21%3E%5C%21x%29%5C%21%3D%5C%21%5Cmathbb%7BP%7D%28Y%5C%21%5Cleq%5C%21-%5Clog%28x%29%2Fz%29%5C%21%3D%5C%211%5C%21-%5C%21x%5E%7B%5Cmu%2Fz%7D.&bg=ffffff&fg=000000&s=2&c=20201002)
![\displaystyle \qquad\qquad\qquad\bar F_{[\![S\mid \Phi]\!]}(z,x)=1-x^{\lambda\pi/z}.\qquad\qquad\qquad (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad%5Cqquad%5Cqquad%5Cbar+F_%7B%5B%5C%21%5BS%5Cmid+%5CPhi%5D%5C%21%5D%7D%28z%2Cx%29%3D1-x%5E%7B%5Clambda%5Cpi%2Fz%7D.%5Cqquad%5Cqquad%5Cqquad+%281%29&bg=ffffff&fg=000000&s=2&c=20201002)