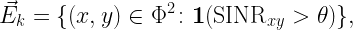In vehicular networks, transceivers are inherently confined to a subset of the two-dimensional Euclidean space. This subset is the street system where cars are allowed to move. Accordingly, stochastic geometry models for vehicular networks usually consist of two components: A set of streets and a set of point processes, one for each street, representing the vehicles. The most popular model is the Poisson line process (PLP) for the streets, combined with one-dimensional PPPs of vehicles on each line (street).
This PLP-PPP model does not have T-junctions, only intersections. Accordingly, all vehicles are of order 2 or 4, per the taxonomy introduced here. The order is determined by the number of directions in which a vehicle can move.
The PLP-PPP is a Cox process due to the independent one-dim. PPPs, and the underlying street system determining the intensity measure (the line process) is also based on the PPP. Consequently, the PLP-PPP inherits a certain level of tractability from the PPP, in the sense that exact expressions can be derived for some quantities of interest. In particular, the SIR distribution (complementary cumulative distribution function, ccdf) at the typical vehicle for a transmitter at a fixed distance can be derived without difficulty. However, the expression requires the evaluation of two nested improper integrals. While such a result certainly has its value, it does not give direct insight how the resulting SIR distribution depends on the network parameters. Also, other metrics that depend on the SIR often require further integration, most importantly the SIR meta distribution, which is calculated from the higher moments of the conditional SIR ccdf (given the point process).
This raises the question whether it is possible to find a closed-form result that is much more quickly evaluated and provides a tight approximation. Simply replacing the PLP-PPP by a two-dimensional PPP produces poor results, especially in the high-reliability regime (where the SIR ccdf is near 1). Similarly, considering only the one street that the typical vehicle lies on (i.e., using only a one-dimensional PPP) ignores all the interference from the vehicles on the other streets, which strongly affects the tail of the distribution.
How about a combination of the two – a superposition of a one-dimensional PPP for the typical vehicle’s street and a two-dimensional PPP for the other vehicles? In this approach, PPPs of two different dimensions are combined to a transdimensional PPP (TPPP). It accurately characterizes the interference from nearby vehicles, which are likely to lie on the same street as the typical vehicle, and captures the remaining interference without the complexity of the PLP. The three key advantages of this approach are:
- The TPPP leads to closed-form results for the SIR ccdf that are asymptotically exact, both in the lower and upper tails (near 0 and near infinity).
- The results are highly accurate over the entire range of the SIR ccdf, and they are obtained about 100,000 times faster than the exact results. Hence, if fast evaluation is key and a time limit of, say, one μs is specified, the transdimensional approach yields more accurate results than the exact expression. Put differently, the exact expression only leads to higher accuracy if ample computation time is available.
- The simplicity of the TPPP extends to all moments of the conditional success probability, which greatly simplifies the calculation of the SIR meta distribution.
The TPPP approach is also applicable to other street systems, including the Poisson stick model (where streets are modeled as line segments of random length) and the Poisson lilypond model, which forms T-junctions (where vehicles are of order 3). For the stick model with independent lengths, the exact expression of the nearest-neighbor distance distribution involves six nested integrals, hence a transdimensional is certainly warranted. More details can be found here.