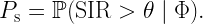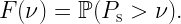Sometimes we read in a paper “the link distance is d meters”. Then, a bit later, “In Fig. 3, we set d=10 m”. Putting the two together, this means that “the link distance is 10 m meters”, which of course isn’t what the authors mean. It is not hard to infer that they mean the distance is 10 m, rather than 10 m2. But then why not just say “the link distance is d” from the outset?
Physical quantities are a combination of a numerical value and a unit. If symbols refer to physical quantities, equations are valid irrespective of any metric prefixes used. For example, if the density of a two-dimensional stationary point process is λ, then the mean number of points in a disk of radius r is always λπr2. We can express the radius as r=100 m or as r=0.1 km or r=10000 cm, and the density could be λ=0.1 km-2 or λ=10-5 m-2. In contrast, if a symbol only refers to the numerical value of the physical quantity, the underlying unit (and prefix) needs to be specified separately, and the reader needs to keep it in mind. For example, writing λ=10 and r=2 does not tell us anything about the mean number of points in the disk without the units. If the density is said to be λ m-2 and the radius is said to be r km, then we can infer that there are 40,000,000π points on average in the disk, but if the radius is r m, then there are a mere 40π points.
Separating the numerical values from the units also comes at a loss in flexibility. The advantage of the SI unit system with its metric prefixes is that we can express small and large values conveniently, such as d=5 nm or f=3 THz. Hard-wiring the units by saying “the frequency is f Hz” means that we have to write f=3,000,000,000,000 instead – and expect the reader to memorize that f is expressed in Hz. One may argue that in this case it would be natural to declare that “the frequency is f THz”, but what if much lower frequencies also appear in the paper? A Doppler shift of 10 kHz would become a Doppler shift of f=0.00000001.
This leads to the next problem, which is that some quantities are naturally expressed at a different scale (i.e., with a different metric prefix) than others. Transistor gate lengths are usually expressed in nm, while lengths of fiber optic cables may be expressed in km, and many other lengths and distances fall in between, say wavelengths, antenna spacing, base station height, intervehicular distances etc. Can we expect the readers to keep track of all the base units when we write “the gate length is u nm”, “the wavelength is v cm”, and “the base station height is h m”?
In conclusion, there is really no advantage to this kind of separation. In other words, having mathematical symbols refer to physical quantities rather than just numerical values (while the unit is defined elsewhere) is always preferable.
Now, there are cases, where it makes perfect sense to omit a unit when defining a quantity, say a density or a distance. For example, the normalized notation r=10 or λ=3 is acceptable (usually even preferred) when the normalization reference can be arbitrary. For example, the classical result for the SIR distribution in Poisson bipolar networks (link distance r, path loss exponent 2/δ, Rayleigh fading) is
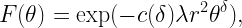
irrespective of whether r is normalized by 1 m or 1 km – as long as λ is normalized accordingly, i.e., by 1 m-2 or 1 km-2). Such scale-free results are particularly elegant, because they show that shrinking or expanding the network does not change the result. They may also indicate that one parameter can be fixed without loss of generality. In this example, what matters is the product λ r2, so setting λ=1 or r=1 is sensible to reduce the number of parameters.
One more thing. The conflation of a unit and a noun describing a physical quantity or device has become somewhat popular, unfortunately. It violates rule of proper English composition and also the guidelines for scientific writing as put forth by, for example, IEEE. Let us hope they do not spread further, otherwise we need to get used to THzFrequencies, cmDistances, MsLifetimes, pJConsumptions, km-2Densities etc. Further, improper capitalization can drastically change the quantities. The gap between a mmLength and a MmLength is 9 orders of magnitude, that between a pASource and a PASource is 27 orders of magnitude, and that between ymGaps and YmGaps is 48 orders of magnitude!