The fraction of reliable links is an important metric, in particular for applications with (ultra-)high reliability requirements. In the literature, we see that it is sometimes equated with the transmission success probability of the typical link, given by

This is the SIR distribution (in terms of the complementary cdf) at the typical link. In this post I would like to discuss whether it is accurate to call ps the fraction of reliable links.
Say someone claims “The fraction of reliable links in this network is ps=0.8″, and I ask “But how reliable are these links?”. The answer might be “They are (at least) 80% reliable of course, because ps=0.8.” Ok, so let us assume that the fraction links with reliability at least 0.8 is 0.8. Following the same logic, the fraction of links with reliability at least 0.7 would be 0.7. But clearly that fraction cannot be smaller than the fraction of links with reliability at least 0.8. There is an obvious contradiction. So how can we quantify the fraction of reliable links in a rigorous way?
First we note that in the expression for ps, there is no notion of reliability but ps itself. This leads to the wrong interpretation above that a fraction ps of links has reliability at least ps. Instead, we want so specify a reliability threshold so that we can say, e.g., “the fraction of links that are at least 90% reliable is 0.8”. Naturally it then follows that the fraction of links that are at least 80% reliable must be larger than (or equal to) 0.8. So a meaningful expression for the fraction of reliable links must involve a reliability threshold parameter that can be tuned from 0 to 1, irrespective of how reliable the typical link happens to be.
Second, ps gives no indication about the reliability of individual links. In particular, it does not specify what fraction of links achieve a certain reliability, say 0.8. It could be all of them, or 2/3, or 1/2, or 1/5. ps=0.8 means that the probability of transmission success over the typical link is 0.8. Equivalently, in an ergodic setting, in every time slot, a fraction 0.8 of all links happens to succeed, in every realization of the point process. But some links will be highly reliable, while others will be less reliable.
Before getting to the definition of the fraction of reliable links, let us focus on Poisson bipolar networks for illustration, with the following concrete parameters: link distance 1/4, path loss exponent 4, target SIR threshold θ=1, and the fading is iid Rayleigh. The link density is λ, and we use slotted ALOHA with transmit probability is p. In this case, the well-known expression for ps is

where c=0.3084 is a function of link distance, path loss exponent, and SIR threshold. We note that if we keep λp constant, ps remains unchanged. Now, instead of just considering the typical link, let us consider all the links in a realization of the network, i.e., for a given set of locations of all transceivers. The video below shows the histogram of the individual link reliabilities for constant λp=1 while varying the transmit probability p from 1.00 to 0.01 in steps of 0.01. The red line indicates ps, which is the average of all link reliabilities and remains constant at 0.735. Clearly, the distribution of link reliabilities changes significantly even with constant ps – as surmised above, ps does not reveal how disparate the reliabilities are. The symbol σ refers to the standard deviation of the reliability distribution, starting at 0.3 at p=1 and decreasing to less than 1/10 of that for p=1/100.
Equipped with the blue histogram (or pdf), we can easily determine what fraction of links achieves a certain reliability, say 0.6, 0.7, or 0.8. These are shown in the plot below. It is apparent that for small p, due to the concentration of the link reliabilities as p→0, the fraction of reliable links tends to 0 or 1, depending on whether the reliability threshold is above or below the average ps .

So how do we characterize the link reliability distribution theoretically? We start with the conditional SIR ccdf at the typical link, given the point process:
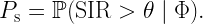
Then ps=E(Ps), with the expectation taken over the point process. Hence ps is the mean of the conditional success probability, and if we consider its distribution, we arrive at the link reliability distribution, shown in blue in the video above. Mathematically,
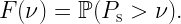
where ν is the target reliability. This distribution is a meta distribution, since it is the distribution of a conditional distribution. In ergodic settings, it specifies the fraction of links that achieve an SIR of θ with reliability at least ν, which is exactly what we set out to quantify.
In conclusion: The fraction of reliable links is not given by the standard (mean) success probability; it is given by the meta distribution of the SIR.

Can one use “reliable” and “successful” interchangeably in the context of the density of reliable/successful links? It may be possible to interpret a reliable link as the one that has a (conditional) success probability larger than \nu, but it may not be exactly the successful link. As you said in the post, a link might be successful in a time slot, but not in an another slot.
LikeLike
In my view there is a clear distinction. “success” refers to a specific event, namely SINR>\theta. It either happens or not. In contrast, “reliable” is a statistical property that involves averaging. So a currently “successful link” may be very unreliable or highly reliable. Conversely, a highly reliable link may be successful or not in a particular moment of time. The probability of the success event, usually called the success probability, can be equated to the reliability.
Next, the fraction of successful links is the standard success probability, by ergodicity. One notion involves spatial averaging, the other ensemble averaging. The problem is that this equality can be misleading – one may wrongly deduce that there are certain links whose transmissions are inherently successful while others’ are not. However, as explained in the post, we cannot make any inference about individual links from the success probability (or reliability).
LikeLike