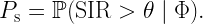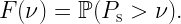The derivation of meta distributions is mostly based on the calculation of the moments of the underlying conditional distribution. The reason is that except for highly simplistic scenarios, a direct calculation is elusive. Recall the definition of a meta distribution
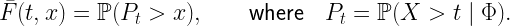
Here X is the random variable we are interested in, and Φ is part of the random elements X depends on, usually a point process modeling the locations of wireless transceivers. The random variable Pt is a conditional distribution given Φ.
Using stochastic geometry, we can often derive moments of Pt. Since Pt has finite support, finding its distribution given the moments is a Hausdorff moment problem, which has a rich history in the mathematical literature but is not fully solved. The infinite sequence of integer moments uniquely defines the distribution, but in practice we are always restricted to a finite sequence, often less than 10 moments or so. This truncated version of the problem has infinitely many solutions, and the methods proposed to find or approximate the solution to the standard problem may or may not produce one of the solutions to the truncated one. In fact, they may not even provide an actual cumulative distribution function (cdf). On overview of the existing methods and some improvements can be found here.
In this blog, we focus on a method to find the infimum and supremum of the infinitely many possible cdfs that have a given finite moment sequence. The method is based on the Chebyshev-Markov inequalities. As the name suggests, it generalizes the well-known Markov and Chebyshev inequalities, which are based on moments sequences of length 1 or 2. The key step in this method is to find the maximum probability mass that can be concentrated at a point of interest, say z. This probability mass corresponds to the difference between the infimum and the supremum of the cdf at z. This technical report provides the details of the calculation.
Fig. 1 shows an example for the moment sequence mk =1/(k+1), for k ∈ [n], where the number n of given moments increases from 5 to 15. It can be observed how the infimum (red) and supremum (blue) curves approach each other as more moments are considered. For n → ∞, both would converge to the cdf of the uniform distribution on [0,1], i.e., F(x)=x. The supremum curve lower bounds the complementary cdf. For example, for n =15, ℙ(X>1/2)>0.4. This is the best bound that can be given since this value is achieved by a discrete distribution.
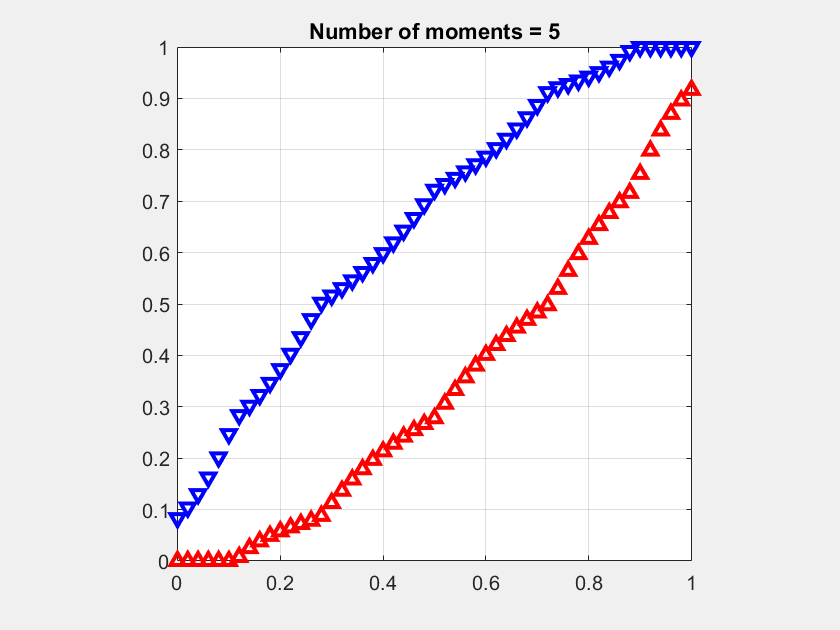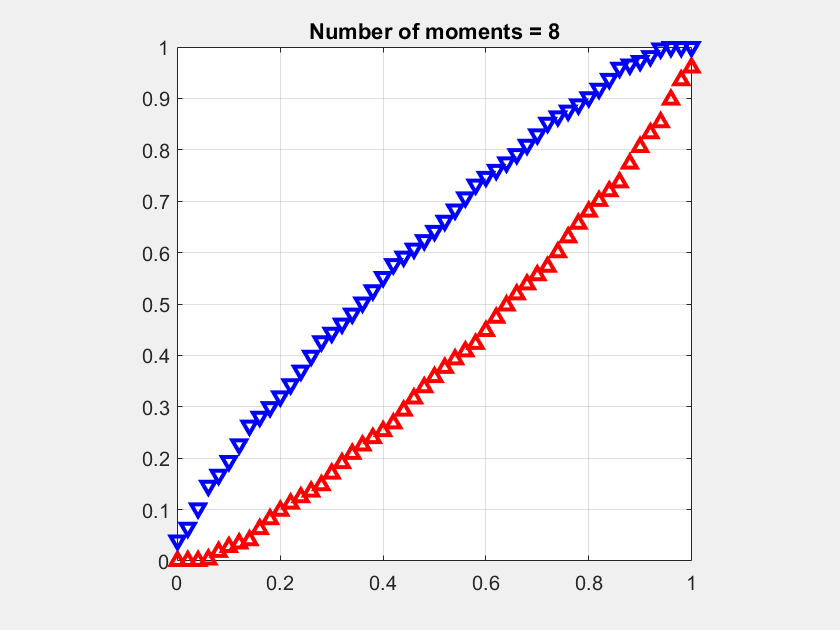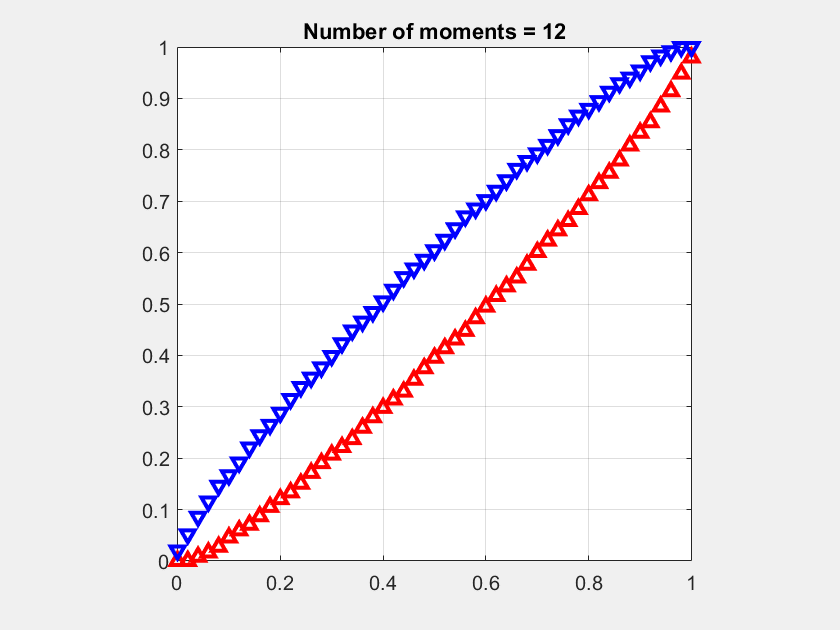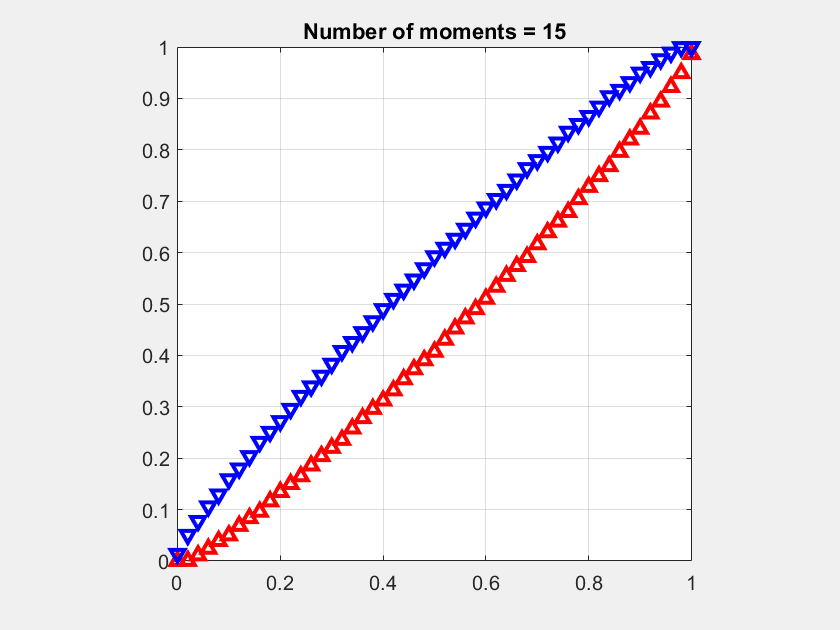
The average of the infimum and supremum at each point naturally lends itself as an approximation of the meta distribution. It can be expected to be significantly more accurate than the usual beta approximation, which is based only on the first two moments.
An implementation is available in GitHub at https://github.com/ewa-haenggi/meta-distribution/blob/main/CMBounds.m.
Acknowledgment: I would like to thank my student Xinyun Wang for writing the Matlab code for the CM inequalities and providing the figure above.




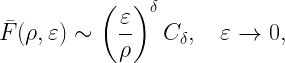

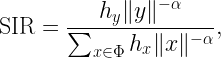
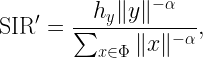


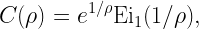
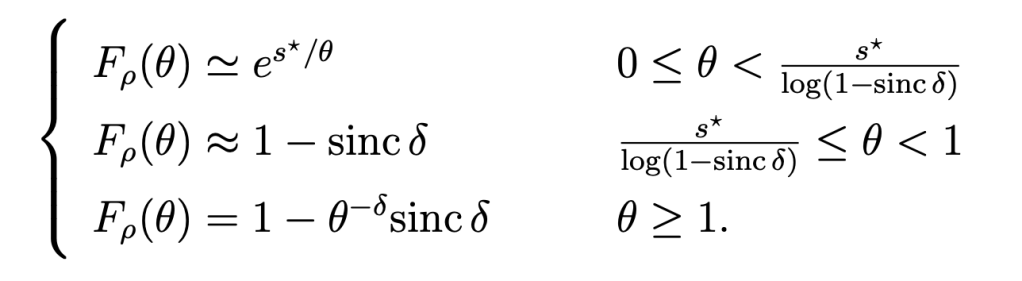


![\displaystyle \bar F_{[\![Z\mid Y]\!]}(z,x)=\mathbb{E}\mathbf{1}(\mathbb{E}[\mathbf{1}(Z>z) \mid Y]>x).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar+F_%7B%5B%5C%21%5BZ%5Cmid+Y%5D%5C%21%5D%7D%28z%2Cx%29%3D%5Cmathbb%7BE%7D%5Cmathbf%7B1%7D%28%5Cmathbb%7BE%7D%5B%5Cmathbf%7B1%7D%28Z%3Ez%29+%5Cmid+Y%5D%3Ex%29.&bg=ffffff&fg=000000&s=2&c=20201002)
![\displaystyle \bar F_{[\![Z\mid Y]\!]}(z,x)=\mathbb{E}\mathbf{1}(\mathbb{E}_X\mathbf{1}(Z>z)>x).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar+F_%7B%5B%5C%21%5BZ%5Cmid+Y%5D%5C%21%5D%7D%28z%2Cx%29%3D%5Cmathbb%7BE%7D%5Cmathbf%7B1%7D%28%5Cmathbb%7BE%7D_X%5Cmathbf%7B1%7D%28Z%3Ez%29%3Ex%29.&bg=ffffff&fg=000000&s=2&c=20201002)



![\displaystyle \bar F_{[\![Z\mid Y]\!]}(z,x)\!=\!\mathbb{P}(U\!>\!x)\!=\!\mathbb{P}(Y\!\leq\!-\log(x)/z)\!=\!1\!-\!x^{\mu/z}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar+F_%7B%5B%5C%21%5BZ%5Cmid+Y%5D%5C%21%5D%7D%28z%2Cx%29%5C%21%3D%5C%21%5Cmathbb%7BP%7D%28U%5C%21%3E%5C%21x%29%5C%21%3D%5C%21%5Cmathbb%7BP%7D%28Y%5C%21%5Cleq%5C%21-%5Clog%28x%29%2Fz%29%5C%21%3D%5C%211%5C%21-%5C%21x%5E%7B%5Cmu%2Fz%7D.&bg=ffffff&fg=000000&s=2&c=20201002)
![\displaystyle \qquad\qquad\qquad\bar F_{[\![S\mid \Phi]\!]}(z,x)=1-x^{\lambda\pi/z}.\qquad\qquad\qquad (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad%5Cqquad%5Cqquad%5Cbar+F_%7B%5B%5C%21%5BS%5Cmid+%5CPhi%5D%5C%21%5D%7D%28z%2Cx%29%3D1-x%5E%7B%5Clambda%5Cpi%2Fz%7D.%5Cqquad%5Cqquad%5Cqquad+%281%29&bg=ffffff&fg=000000&s=2&c=20201002)