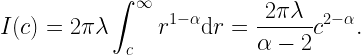When applying simalysis as illustrated in the previous post, the question arises where to put the boundary between the part of the point process that is simulated and the part that is analyzed. Specifically, we may wonder whether we can reduce the simulated part to only a single point (on average), i.e., to choose the number of simulated points to be Poisson with mean 1 in each realization.
Let’s find out, using the same Poisson bipolar model as in the previous post (Rayleigh fading, transmitter density 1, link distance 1/4).

Fig. 1 shows the simulated (or, more precisely, simalyzed) result where the 500 realizations only contain one single point on average. This means that about 500/e ≈ 184 realizations have no point at all. We observe good accuracy, especially at small path loss exponents α. Also, the simulated curves are lower bounds to the exact ones. This is due to Jensen’s inequality:
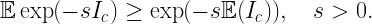
The term on the left side is the exact factor in the SIR ccdf due to the interference Ic from points outside distance c. It is larger than the right side, which is the factor used in the simalysis (see the Matlab code). This property holds for all stationary point processes.
But why stop there? One would think that using, say, only 1/4 point on average would be (essentially) pointless. But let’s try, just to be sure.

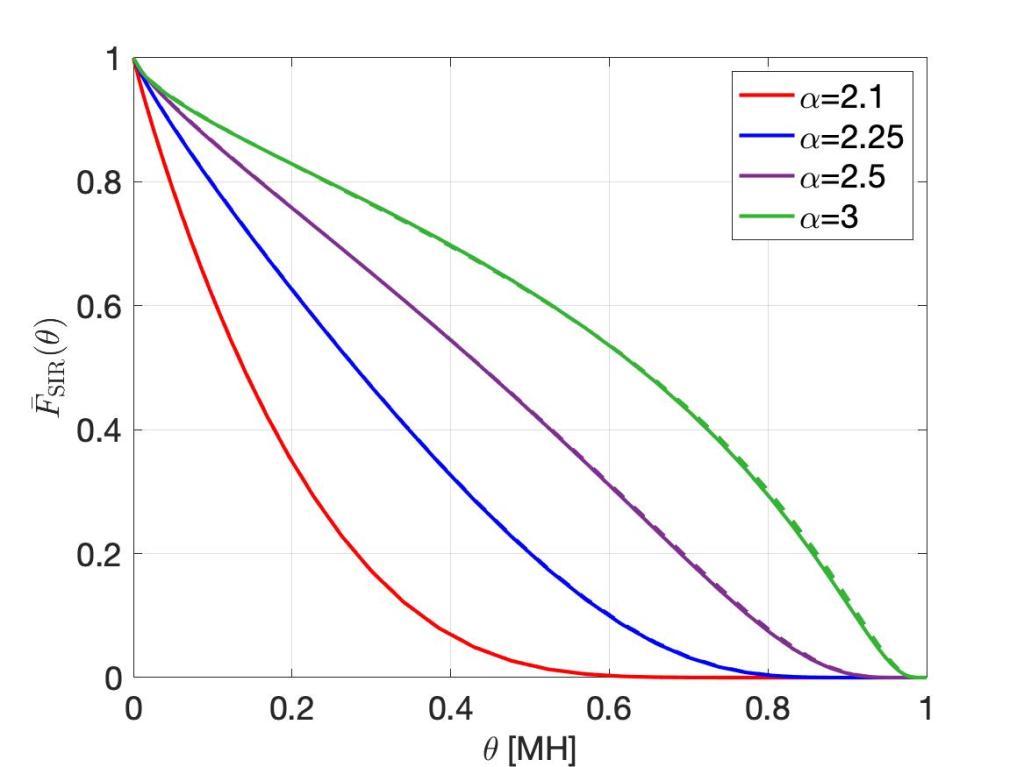
Remarkably, even with only 1/4 point per realization on average, the curves for α<2.5 are quite accurate, and the one for α=2.1 is an excellent lower bound! It is certainly much more accurate than a classical simulation with 500,000 points per realization (see the previous post). Such a good match is quite surprising, especially considering that 1/4 point on average means that about 78% of the realizations have 0 points, which means that in about 390 out of the 500 realizations, the simulated factor in the SIR ccdf simply yields 1. Also, in the entire simalysis, only about 125 points are ever produced. It takes no more than about 1/2 s on a standard computer.
We conclude that accurate simulation (simalysis, actually) can be almost point-less.