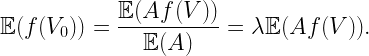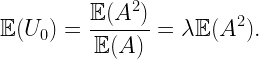When simulating a point process to characterize the performance of the typical point (typical user or receiver), a conditioned version of the point process given a point at the origin o may not be available. It is then tempting to choose the “next best” point as a substitute, which may be the point closest to the origin. (Whether the coordinates are then shifted so that this point is at o is irrelevant.) The goal of this post is to show that this point is not typical, i.e., producing many realizations of the point process and evaluating the performance at this point does not yield the performance of the typical point. I call the point closest to o after averaging over the point process the 0-point. Put differently, the 0-point is the typical point among all points closest to o across the realizations of the point process. In a cellular network, the 0-point is the nucleus of the 0-cell (see this post), hence the term.
For simplicity, let us consider the homogeneous PPP of intensity 1 and focus on the probability that a disk of radius r centered at a point contains no other points, which we refer to as the NOPID (no other point in disk) probability. Equivalently, it is the probability that the nearest neighbor is at distance at least r. For the typical point, the NOPID probability is exp(-πr2). For the 0-point, let D be its distance from o. Given D, the disk of radius D centered at o, denoted as b(o,D), is empty, so the points excluding the 0-point form a PPP on ℝ2\b(o,D), and the NOPID probability is the probability that b((D,0),r)\b(o,D) is empty. This region is shown in blue in the movie below for different r given that the 0-point is at (1,0), i.e., D=1. For r<2D, it is moon- or crescent-shaped, while for r>2D, it is a disk with a hole.
Letting A(r,d)=|b((d,0),r)\b(o,d)|, the (unconditioned) NOPID probability is 𝔼(exp(-A(r,D)), where D is Rayleigh distributed with mean 1/2. It can be expressed as

where
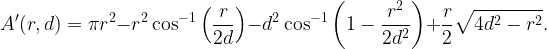
is the area A(r,d) for r<2d. For r>2d, A(r,d)=π(r2–d2), which results in the first term in (1).
The NOPID probabilities of the 0-point and the typical point are compared below. It is apparent that the 0-point is more isolated than the typical point.

By integrating the NOPID probability of the 0-point, we obtain the mean nearest-neighbor distance as 0.5953. This is almost 20% larger than that of the typical point, which is 1/2. The difference between the two NOPID probabilities is not just in the mean, though. They differ qualitatively in the tail. For large r, it follows from (1) that the ratio of the two NOPID probabilities approaches πr2/4. This implies that a Rayleigh distribution with adjusted mean will not provide a good fit to the NOPID probability at the 0-point.
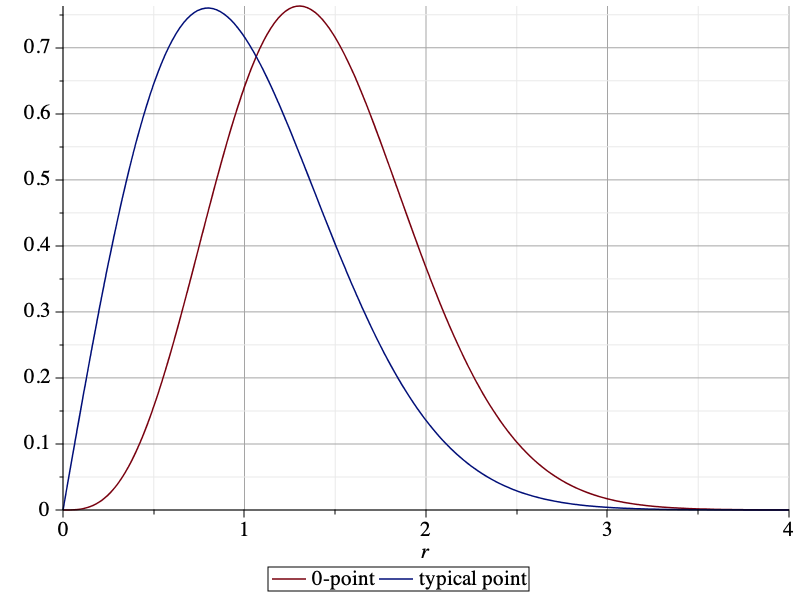
The difference is even more pronounced if we consider directional nearest neighbors. If we consider a sector of angle π/2, then the nearest neighbor of the typical point is at distance 1 on average, irrespective of the orientation of the sector. For the 0-point, in the direction opposite from o, the mean distance is also 1, since on that side, the PPP is unaffected by the empty disk b(o,D). In the direction towards o, however, the distance is significantly larger, with a mean of 1.4205. The plot below shows the pdf of the directional nearest-neighbor distance of the 0-point oriented towards o (red) and the pdf of the directional nearest-neighbor distance of the typical point (blue), given by (π/2)r exp(-(π/4)r^2). The pdfs are the negative derivatives of the NOPIS (no other point in sector π/2) probabilities.
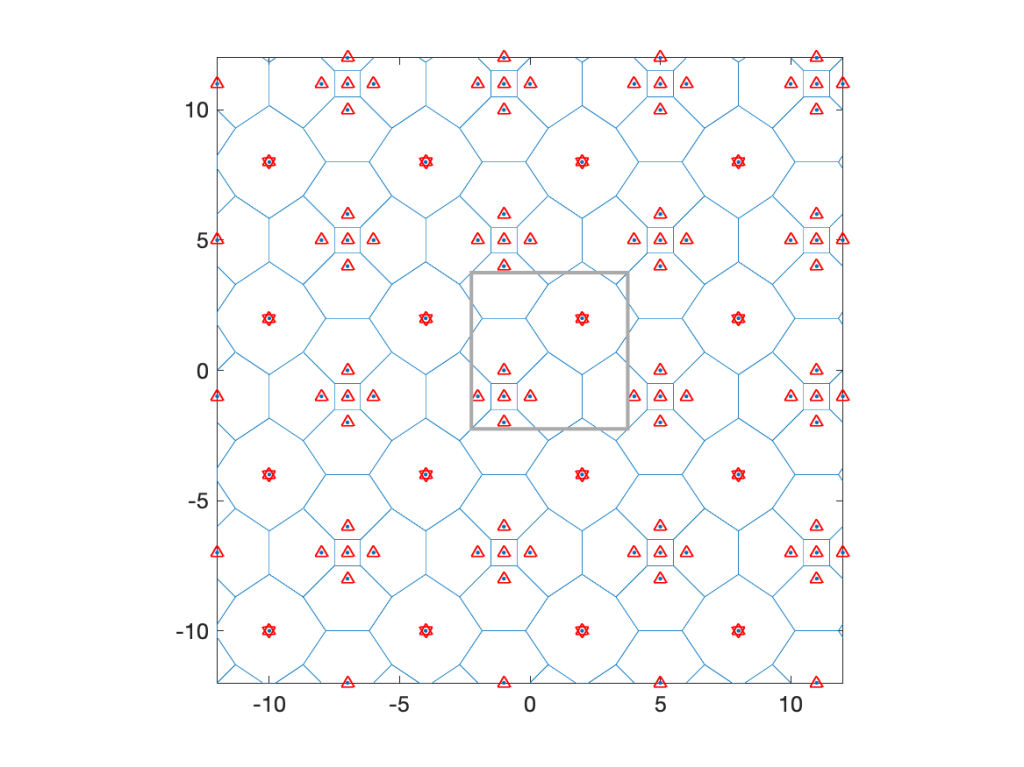
When applied to cellular networks (with nearest-base station association), the 0-point is the base station serving the typical user (at o). The discussion here reveals that the 0-base station behaves differently from the typical base station. In particular, the point process of the other base stations viewed from the 0-base station is highly non-isotropic. In the direction of the typical user, the nearest other base station is much further away than in the opposite direction. This fact is consistent with the conclusions from this post on the shape of the 0-cell in the Poisson-Voronoi tessellation.