These days, “connectivity” is a very popular term in wireless networking. Related to 5G, typical statements include
- “5G will be the main driver of wireless connectivity.”
- “5G is designed to provide more connectivity.”
- “5G provides 1 million connected devices per square km.”
There is also talk about “massive connectivity”, “poor connectivity”, “intermittent connectivity”, “high-speed connectivity”, “dense connectivity”, “sparse connectivity”, “ubiquitous connectivity”, “heterogeneous connectivity”, “hard connectivity”, “soft connectivity” etc. My favorite, though, is “connection-less connectivity”.
While everyone has a (vague) sense of what “connectivity” or “being connected” could mean in a wireless context, it is quite surprising to see that there is hardly any definition to be found in the literature. Being vague and call on some common sense is probably acceptable in media articles targeted at a general audience. However, in the technical journals, including the IEEE transactions, I would expect that this term would be rigorously defined. However, in the vast majority of articles, this is not the case; there are papers on IEEE Xplore that mention “connectivity” several dozen times but the authors never explain what they mean by it.
For instance, if the so-called “internet-of-things” (IoT) is claimed to soon “connect” billions of devices, does that mean that each device can communicate to each other one at a certain rate with a certain latency and a certain reliability? If yes, what are the rate, latency, and reliability? Or does it mean that over the course of a long period (say a day), they can all send a message to the wired (internet) backbone? Again, what is the reliability of that happening? Or does it mean that all the devices are capable (in principle) to establish a TCP connection to some server? Similarly, with one million “connected” devices per square km in 5G, what are they “connected” to? Each other, or a base station? At what rate/delay/reliability? It is clear that at the physical and link/MAC layers, any notion of “connectivity” would need to include probabilities (reliabilities), rates (throughput), and delay (latency). But such specifications are sorely missing in most of the literature. Further, extra attributes such as “massive”, “poor”, “ubiquitous” lack definitions also, and in view of half-duplex, channel access and other resource constraints, all connectivity is “intermittent”, rather than permanent.
At the transport layer, the situation is not clear, either. Two devices can be declared “connected” if a TCP connection has been established (although this does not guarantee that they can actually exchange messages in a given time). Conversely, two devices can successfully communicate without begin “connected” in the sense of the transport layer if they use a connection-less protocol (UDP). So at this level, being “connected” is neither sufficient nor necessary for communication.
At a higher level of abstraction, if a network is represented as a graph, there is a clear (mathematical) definition of what it means for the network to be connected. However, a (standard) graph is a model for a wired network, not a wireless one, for it does not account for fading, beamforming, power control, channel access, interference, and half-duplex constraints. Fading and rates could be incorporated in a weighted graph, half-duplex communication in a directed graph (digraph), and channel access in a dynamic (time-dependent) graph. Interference, however, is much more complicated to incorporate in a graph model since the success of a transmission may depend on a large set of interfering transmitters, their channel states, and their transmit powers. Also, if in a dynamic graph model a link (directed edge) from A to B exists at a certain time k and a link exists from B to C at time j, a path (or connection) from A to C is only formed if k<j.
So what is a meaningful graphical model for a wireless network based on which connectivity can be rigorously defined? Let us assume that a transmission succeeds (i.e., a link exists) if the SINR at the receiver exceeds some value θ that is determined based on the coding and modulation schemes. This model incorporates all the physical layer aspects mentioned above and, if made dynamic, channel access and other time-varying aspects.
Letting Φ denote the set of node locations (vertices), the SINR-based (geometric) digraph at time k has the directed edge set
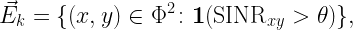
SINRxy is the SINR at y when it attempts to receive from x at time k. The SINR condition implies that for an edge to form, x is transmitting at time k while y is not (unless y is full-duplex-capable). Then

is a directed multigraph (multiple edges are allowed between two vertices) that captures the entire history of successful transmissions in the network up to time n. It may be called the space-time SINR multigraph at time n. Figure 1 shows movie of the evolution of a network with 36 nodes that are transmitting independently with probability 1/4 in each time slot (slotted ALOHA).
Fig. 1. Example of space-time SIR multigraph with θ=3, path loss exponent 4, no noise, and Rayleigh fading. Filled circles indicate transmitters. Edges get thicker each time their link succeeds, and they turn red when bidirectionally is first achieved.
Figure 2 shows a larger network of the same type, with 400 nodes.
Fig. 2. Same as Figure 1 but with 400 nodes.
This graph reveals how many nodes can be reached from a given node within a certain time, or how many other nodes a node can receive a message from. Information in the network propagates along causal paths, i.e., paths where the first link is established before the second before the third, etc. To simplify the identification of such paths, the time index when an edge is established can be added as an edge weight.
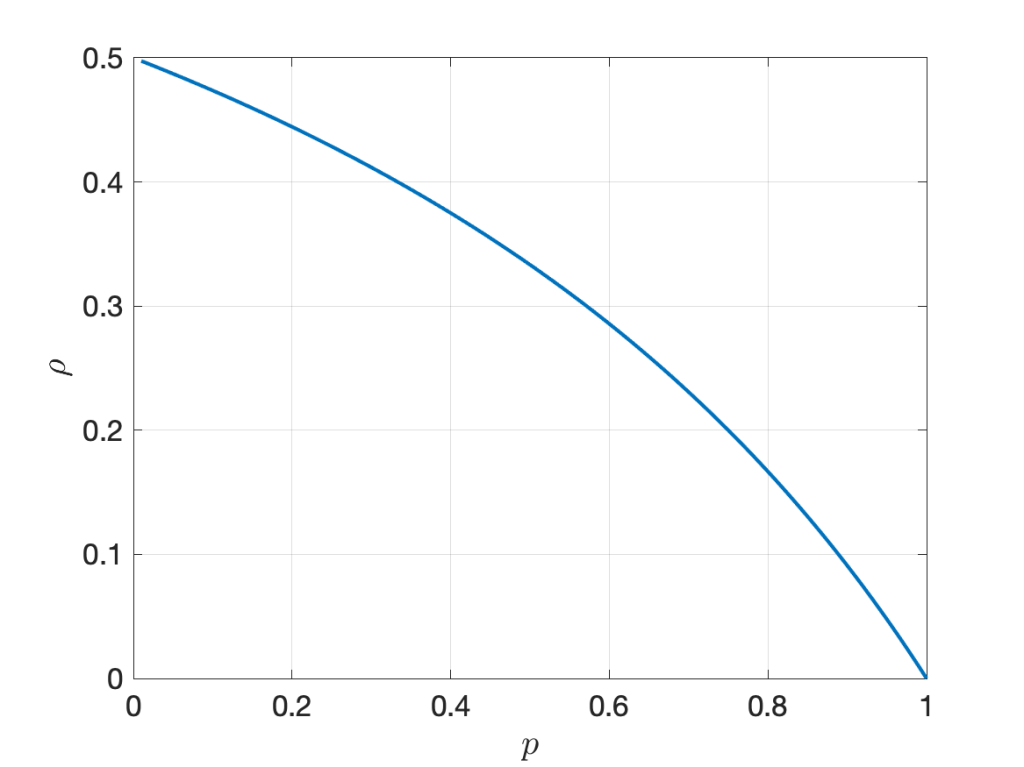
Based on this graph, notions of percolation and connectivity can be rigorously defined. For connectivity, a natural definition is that the network is connected if causal paths exist between all pairs of nodes. A fairly general result can be proven without much difficulty: For arbitrary deterministic Φ∈ℝ2, ALOHA with transmit probability 0<p<1, a path loss exponent greater than 2, the graph G∞ is almost surely connected if the (independent) fading variables have infinite support, irrespective of the noise level.
When an analysis for a deterministic set of locations Φ seems hard, randomizing it to a point process may improve the tractability. A good starting point, as usual, is the PPP. For the PPP, one can hope to answer questions such as:
- How long does it take on average for a message to propagate from node x to node y (first-passage percolation)? Here x and y are deterministically added to the node set.
- Under which condition is the average time for a node to reach any other node infinite? (If this average time is infinite, the node could be declared isolated.)
- Is the propagation speed, defined as the time it takes for information to travel from x to y normalized by their distance, zero or positive asymptotically as the distance grows to infinity?
Based on these results, parameters such as the transmit probability can be optimized.