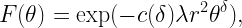Network slicing is a warm topic these days. Here we discuss cell slicing, where a polygon is cut in three pieces (sub-polygons) by two lines through its nucleus and a random point, respectively. First, as a sequel to this post, we focus on the 0-cell in the Poisson-Voronoi tessellation, which is the Voronoi cell of a PPP that contains the origin.
As in that earlier post, we rotate and shift the 0-cell so that its nucleus is at the origin and the point located uniformly randomly in the cell is to the right (on the positive x axis). In a cellular network application, the nucleus (now at the origin) is the location of the base station, while the random point is the typical user. Then we draw vertical lines through the origin and the random point and calculate the areas of the polygons to the left of the origin and to the left of the random point. This movie shows a number of realizations of this setup:
For intensity λ=1, the 0-cell in the Poisson-Voronoi tessellation has a mean area of 1.280176, obtained by the numerical evaluation of an integral. The polygon to the left of the nucleus o, shown in green in the movie, has a mean area of 0.517649, also obtained by numerical integration. The red polygon, to the right of o and to the left of x, has a mean area of 0.529111, obtained by simulation. Relative to the total mean area, we thus have:
- Mean area to the left of o: 40.4%
- Mean area to the left of x: 81.8%
- Mean area to the right of x: 18.2%
Hence, on average, almost 60% of the (other) users in the cell are on the same side of the base station as the typical user, and the mean area to the left of the typical user is larger than the entire mean area of the typical cell (which is 1 for λ=1). Also, more than 18% of the users are “behind” the typical user.
Not surprisingly, the area fractions are quite similar in the typical Poisson-Voronoi cell. (Note that the uniformly random point in the typical cell does not correspond to the typical user of a user point process that is independent of the base station process – see this post). These percentages (area fractions) for the typical cell are all simulated:
- Mean area to the left of o: 39.8%
- Mean area to the left of x: 81.3%
- Mean area to the right of x: 18.7%
How unusual are these area fractions? Let us compare them with those in the disk, which is, in some sense, the ideal cell shape. In the disk, with the nucleus o at the center, the mean area fraction to the left of o is trivially 1/2, while the area to the left of a uniformly random point is easily determined to be 7/8. This shows that the (roughly) 2/5 – 2/5 – 1/5 split in the typical Poisson-Voronoi cells is relatively far from the 1/2 – 3/8 – 1/8 split of the disk. How about regular polygons with a finite number of sides? The second movie shows some realizations for 3,4, … ,10,12,15,20,32 sides.
As expected, for a larger number of sides the area fractions approach those of the disk. Here is a plot of the relative deviations to the disk of regular polygons, where o is the centroid:

For instance, for the triangle, the area fraction to the left of o is 0.516, which is 3.2% larger than for the disk. Hence the first blue point in Fig. 1 (top left), corresponding to 3 sides, is at 3.2. To better see how the deviations behave for 5 or more sides, here is another version of the figure that shows only pentagons and higher.

From the blue curve it is apparent that the area to the left of the center is always exactly one half if the number of sides is even. The reason is that with an even number of sides, the polygons to the left of o and to the right of o are always congruent irrespective of the location of the random point. We also see that the hexagon is quite close to the disk already, with a mere 0.15% deviation from the 7/8 area fraction (to the left of x) of the disk.